
.jpg "Call center employees working in an open plan office space.")
Enterprises are rapidly moving data and processing to the cloud. Today’s need to support remote workers has increased the pressure to migrate applications and data quickly to the cloud. Until recently, when it came to protection for cloud data, I considered encryption the primary method. Then a few months ago, I came across a new technology called microsharding which disrupted my viewpoint.
Last November, I wrote an article for Computer Weekly that covered some of the concerns related to protecting cloud data and since then my interest in this topic has increased. There are several concerns when it comes to putting sensitive data in the cloud. Most enterprises worry what would happen if their cloud data were breached. For instance, if a cloud admin account is breached, the data stored would likely be compromised. Even if encrypted, the cloud admin often has the keys to decrypt the data. Encryption is relatively straightforward, but key management can be more complex. If the key is lost, the data cannot be decrypted. Moreover, if the key needs to be changed or a stronger encryption algorithm used, all the encrypted data must be re-encrypted – often an expensive and time-consuming task. These are the reasons why cloud data is more likely to be in plaintext than encrypted.
Data stored in the cloud may be subject to privacy regulations like the EU’s GDPR, California’s CCPA, or HIPAA for health-related data. Enterprises inside and outside the US worry that data stored at a US cloud provider may have to be turned over to the US government if subpoenaed, even if the data is stored at a cloud provider’s systems located outside the US or the data is encrypted, but the keys are managed by the cloud provider. Moreover, GDPR compliance has become more difficult for many US enterprises since the EU’s highest court recently struck down Privacy Shield on July 16, 2020.
A new approach to data privacy
A few months ago, I had a conversation with Bob Lam, the CEO of a company called ShardSecure that came up with an innovative, new way to protect data – microsharding. I became so excited by what I learned that I soon decided to become an executive advisor to ShardSecure.
You may have heard of sharding which has long been used by storage companies to improve performance. Basically, files or volumes are split up into multiple pieces and stored in different locations so that I/O can be done in parallel to improve performance. Normally these pieces are a few thousand to a few million bytes in size.
Microsharding also splits a file up into multiple pieces, but the pieces are extremely small. Theoretically as small as a single byte, but in practice each microshard tends to be just a few bytes. Each of these microshards are stored in different locations. So, for instance, they could be spread across multiple cloud providers like Amazon, Microsoft, or Google. Storage locations could even include on-premise locations.
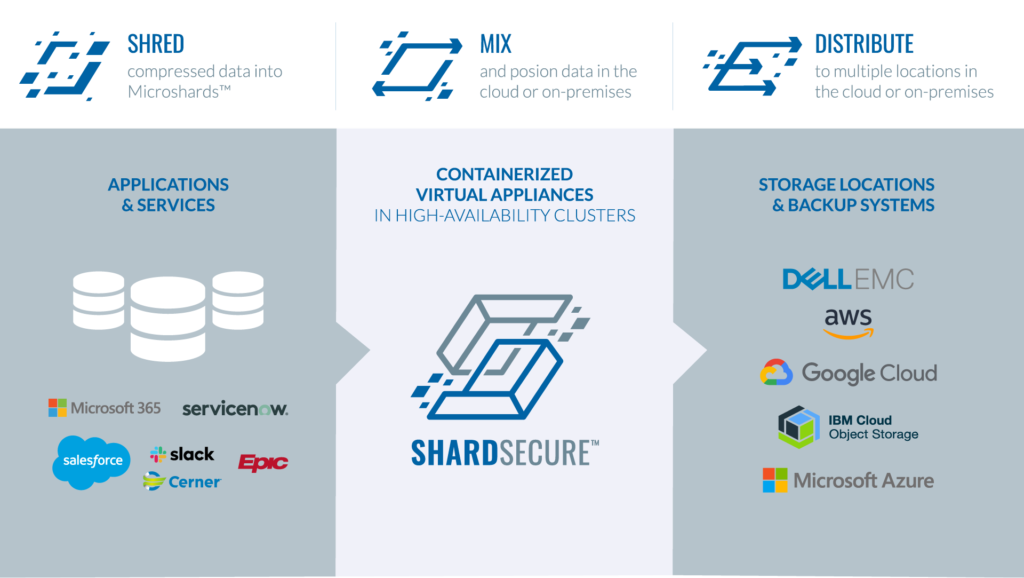
Because the microshard pieces are so small – often just 4 bytes, no single piece yields sensitive information. For instance, 4 bytes is too small to reveal a social security number, credit card number, or e-mail address. Moreover, since the pieces are spread across multiple locations, even if attackers succeeded in breaching a cloud or on-premise storage area, they would not have enough pieces to put the file back together.
Moreover, the microsharding process can also include the injection of poison data and use of compression, adding to the difficulty of re-constructing files from raw storage areas. To reconstruct the files, attackers would need the microshard engine, pointers, and host map file. So, of course, the microshard engine, pointers and host map file do need to be protected from attackers. The host map file is kept separate from the engine, ideally offline.
Microsharding reduces the huge attack surface of the applications and the entire data storage area (gigabytes to petabytes) to the small attack surface of the microshard engine, pointers, host map file and applications (just megabytes). If attackers breach a cloud admin account for one cloud provider, the microsharded data on that cloud provider cannot be used to reconstruct any files or even a small amount of sensitive information. Even if attackers breached all the enterprise’s cloud storage, the microsharded data could not be put back together without access to the microshard engine, pointers, and host map file. Cloud admins and nearly all other admins should never have access to any of these items.
Eliminating the Sensitivity of Data
With microsharding, originally sensitive data has been split into so many small pieces stored in different locations, that I believe it no longer needs to be considered sensitive data. This may mean that the data storage areas may no longer need to be considered in scope from certain regulatory and audit perspectives. Reducing the data sensitivity surface in this fashion speeds cloud migration and yields improved operating efficiencies. If microsharding is used, I recommend that auditors and regulators focus on the security of microshard engines, pointers, and host map file as well as the applications.
From an application perspective, files are stored and accessed in the same fashion they would be for a normal file system. In most cases, applications can function with microsharded files without having to be changed. Moreover, an enterprise could do both microsharding and encryption for two layers of data protection for highly sensitive data.
Protection and Performance Gains
Adding security usually comes at a performance cost. For instance, adding encrypting slows down reading and writing data. However, since microsharding allows for parallel I/O to multiple storage locations (just likely regular sharding), in most cases microsharding improves performance while providing data protection. I cannot think of another instance where adding security results in a performance improvement. A genuinely nice bonus and yet another reason to consider microsharding to protect your data.











